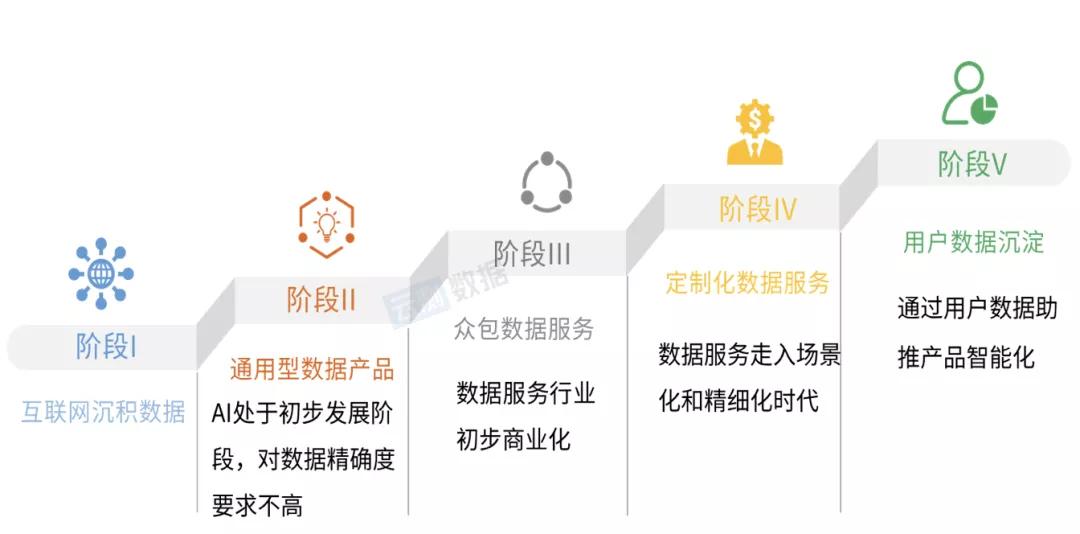
到处都不是智能的:人工智能数据的“消费升级”才刚刚开始
随着“新基础设施”的吹响,每个人肯定都从各种渠道感受到了工业智能的火热。
这一次,人工智能不再停留在“人工智能再一次粉碎人类”的科幻故事中,而是体现为一种社会通用技术,家庭、汽车、超市、3C产品等各个领域都开始以人工智能形象高频率宣传。
其中,——数据是人工智能三要素(包括数据、算法和计算能力)中最基本、最核心的部分,自然成为烹饪行业智能精致化不可或缺的原材料,越来越受到人们的关注。
如果我们把工业智能的红利视为一块等待分割的蛋糕。那么坐在电脑前一点一点地给图片或文字贴标签的数据注释者可能就是在智能肥沃的土地上种植小麦的人。
这些加工过的食物被算法工程师拿走,喂给机器,教它们区分猫和狗、行人和交通灯。“这些天天天天气不好”是什么意思.

听起来“种植”人工智能数据很简单。事实上,在人工智能的早期发展阶段,人工智能的数据收集和注释往往被视为“没有障碍”的东西,甚至被称为新时代的血汗工厂。
然而,就像吃太多粗粮总是开始追求健康、有机和精细加工一样,人工智能数据产业已经开始了一场我们可以看到的“制造业升级”。
工业智能的味道,你和数据想知道吗
尽管人工智能数据不是算法训练的唯一元素,但它绝对是不可缺少的一部分。
一方面,人工智能数据越丰富越便宜的领域越有可能产生人工智能火焰。例如,机器翻译已经发展了几十年,积累了大量的双语语料库。因此,深层神经网络的引入使得翻译系统的效果很快超过了基于统计模型的统计机器翻译。如今,NWT神经机器翻译早已成为智能语音产品的标准。
此外,人工智能数据的质量也决定了人工智能产品是否符合使用场景,这将影响用户体验甚至产品生命周期。在挖掘人工智能产业化丰富的矿井时,人工智能数据的重要性怎么强调都不为过。
因此,一个专业的第三方人工智能数据产业链应运而生,以满足高质量和大规模数据的需求。
然而,当人工智能取得胜利时,人工智能数据产业的限制随之而来。

首先,传统的爬虫或众包模式收集了大量数据,这使得很难满足高性能和高精度算法的数据要求。例如,在金融等场景中,银行可能要求人脸识别算法的准确率达到99.99%,从而达到保护客户财产和防范安全风险的水平。传统的平面人脸数据明显不足,需要维度更丰富、角度更多样的三维人脸图像来训练所需的算法。
此外,机器学习的数据依赖性也增加了人工智能训练的直接成本。无论是收集或购买数据本身的支出,还是调用数据增强技术来增加数据样本,背后都有不小的成本。
至于胶囊网络、小样本甚至零样本学习等。这在人工智能学术界刚刚出现,虽然不受数据规模的限制,但目前还处于实验阶段,行业的成熟度和稳定性是不可预测的,这与实际情况相差甚远。因此,目前,以深层神经网络为核心的机器学习仍然是人工智能产业化的技术支撑。这也决定了人们对人工智能数据的渴望,这种渴望将一直伴随着人工智能产业的发展一段时间。
从工业化和工程化的逻辑角度来看,今天的企业希望创造出具有正面效果和声誉的人工智能产品,而他们可能购买的通用“面粉”已经不能满足挑剔的用户,他们必须学会自己培育数据的沃土。
从夜晚的南风,小麦被黄色覆盖:当人工智能数据场景成熟时,
有了新的基础设施,人工智能数据产业正以比预期更快的速度增长。
这没有其他原因。数字技术与成千上万个行业的融合是当今中国广泛发展的主旋律,而数据则是遍布全球的种子,等待着智能的收获。
那么,需要什么样的种植逻辑才能让它们茁壮成长,有资格进入生产车间,并最终成为滋养社会智慧的高营养食品呢?答案也可能隐藏在中国的“农业人才”中:
首先,尊重法律的专业化。
我们知道一些强大的技术公司,如英美烟草,经常建立自己的数据中心来改进他们的算法。对于大型企业来说,他们面临着数据的洪超,爆炸性的创新将不可避免地带来数据规模的爆炸性增长。据预测,到2025年,80%的计算将来自人工智能计算,涉及的数据将高达180亿,比现在高四倍。在这样一个庞大而复杂的数据社区中,显然很难找到最适合自己土壤的“种子”。

此前,当谷歌工程师被问及众包平台M-Turk(在公共平台上发布任务,参与者可以自由申请)的效果时,他们声称“恢复的数据是混合的”。
用人工智能的话来说,“垃圾输入,垃圾输出”,如果你被算法垃圾成分所喂养,很可能会发展出没有监督学习的产品口碑崩溃的焦点。
例如,以前市场上出现过一个为青少年设计的智能扬声器,在对话中突然出现了咒骂。原来在培训过程中数据集没有得到很好的清理,导致不良数据混入,使人工智能化身为“安祖人”,厂商不得不暂时停止通话,重新进行大规模的内部审核。
如果被限制的数据再次被不小心使用,如欧盟的GDPR一般数据保护条例的红线,它将不仅失去当年的收获,而且可能获得一大笔赔偿。谷歌听了沉默,脸书听了眼泪,这是事实。
数据质量难以控制,企业的努力很可能会直接变成秋风中的寂寞。因此,一个更专业的数据收集和注释平台已经成为珍惜正确时间和地点的人工智能企业家的必要合作伙伴。
第二,因地制宜。
在商业人工智能数据平台中,“基于人工智能的着陆场景”是一种相对较新的模式。
开源数据集不香,还是通用数据不便宜?场景数据的流行可能与人工智能计算产业的下一个发展可能触及的矛盾有关,即竞争。
众所周知,人工智能已经成为GPT的一项通用技术,这也意味着它将以更广阔的姿态融入人类社会,并在此基础上生产新的产品和技术,甚至更新生产和组织方法。
因为它是GPT,这意味着泛人工智能算法不再稀缺,而是在日常生活中遍布水和空气。如何在人工智能产品中与同行竞争,从人工智能数据中重新确立自己的核心优势,已经成为科技企业的必然选择。
例如,在过去,尚超的商店中没有一家是智能的,但是现在几乎每个商店都在尝试引入零售智能解决方案。在这种情况下,拥有超级零售商并掌握了自己专属场景数据的企业主可以更准确地了解自己的业务状况。例如,在此基础上,了解顾客面对货架和在现场走动的表情,有助于判断展示方案和个性化营销推广,进一步提高转化率和回购率。

获取并向算法交付更高级别的场景数据以供使用并不是一件简单的事情。
云测量数据总经理贾亚航举了一个例子。例如,在网上订票这样的对话场景中,有很多表达方式,比如“有去XX的航班吗”和“帮我查一下机票”.如何让人工智能助手们在不同的表达方式中理解彼此的意图,需要人工智能数据服务企业与预订平台精心对接,在标注时进行适当的拆解和操作,因地制宜,将大量高质量的数据转化为垂直行业的智能养分。
一个有趣的数据是,尽管我们今天听到了太多关于人工智能的消息,但人工智能与工业结合的总渗透率只有4%。在未来很长一段时间内,值得关注的是数据场景的投注。
第三,提高能源效率的工程。
当然,随着数字经济进入成熟阶段,不言而喻地在人工智能上花很多钱是不可能的。企业在选择数据模式时必须考虑投入产出比。
那么,当场景数据很大时,它能最大化工业智能的回报吗?
答案是,不一定。场景数据的成本并不低,这里生动地反映了“有多少智能就有多少劳动力”。一个人工智能算法平台的工作人员曾经告诉我,为了训练一个能够准确识别人体运动的模型,他们合作的3D建模数据团队会雇佣人员在姿势采集中心拍摄简历数据,因为数据量太大,只能放在硬盘上,工作人员不停地来回走动,将数据发送到实验室。
这听起来一点也不“高科技”吗?
因此,如果工人想尽最大努力,他们必须首先磨利他们的工具。随着基于场景的人工智能数据产业的发展、工程能力的提高和效率工具的引入,场景数据的整体成本将接近商业平衡点,降低人工智能企业的成本风险。
显然,人工智能数据场景不仅是工业人工智能的唯一途径,而且还有大量的冰原等着被切开。
穿透数据冰层:如何在云测量数据的工业方面种植人工智能
当社会经济和智能技术开始结合时,场景数据的工业服务提供商也开始出现。
目前,成立于2011年的Testin Cloud Test凭借其人工智能数据采集和标注品牌——,已成为中国市场人工智能数据场景的首选。
人工智能数据土壤上的冰层是如何被云数据根除的?
1.手锄犁五金。
场景数据的采集和标注有很多难点。例如,自然语言处理、计算机视觉等。不仅需要标注者准确理解相关语义,还需要根据具体的行业需求进行标注。
为了保证人工智能数据的高质量交付,云测量数据在华东、华北和华南设有数据标注基地和数据采集现场实验室,确保人工智能数据的专业化、场景化和精细化。
贾雨航(云测量数据总经理)给我们举了一个例子。为了帮助疲劳检测系统准确判断驾驶员的状态,疲劳状态数据是必不可少的。因此,云测量数据可以恢复驾驶场景中的疲劳驾驶状态,从而有助于采集符合真实场景的疲劳数据。让训练算法模型准确识别并给出预警,保护人员的行车安全。
此外,为了提高人工智能数据的标注效率,已经开发了许多用于云数据测量的工程工具,数据标注工具的技术含量也在不断提高。
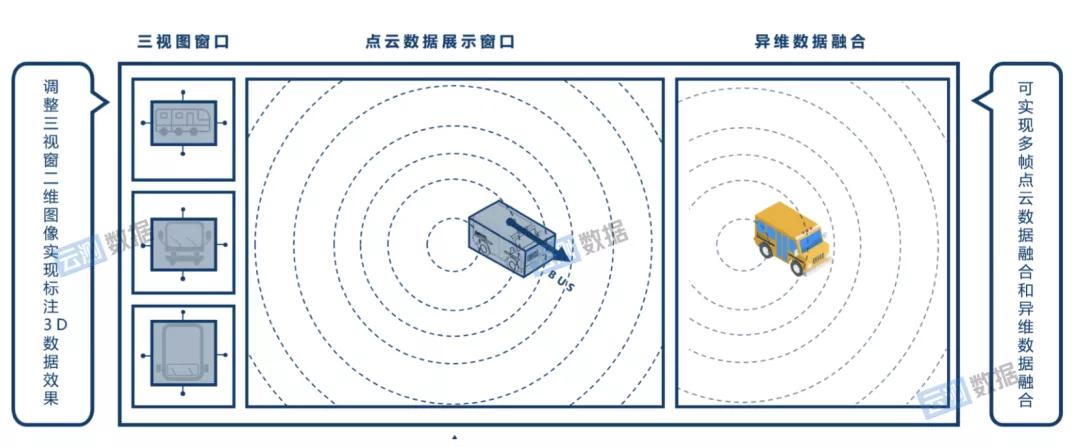
例如,在自主开发的云测量数据标注平台上,渲染引擎针对三维点云标注系统进行了优化,可以整合多帧点云数据和非维度数据,使数据视图一目了然,保证整个过程的流畅和快捷,从而减轻标注人员的重复劳动压力。
2.悄悄滋润事物的软件。
在人工智能的世界里,我们总是强调硬件——更大的计算能力、更好的数据和更好的算法。拥有这些意味着一切吗?显然情况并非如此,否则迪普迈德将是商业化方面最成功的人工智能公司。
从技术概念到行业落地的管理逻辑就像行业上空的春雨,“风潜入夜,悄悄滋润万物”。
我们都知道“好雨知道季节”。“好”在哪里?
幸运的是,到时候。例如,Testin cloud measurement在企业服务领域积累了近9年的经验,其管理模式使数据采集和标注不再是枯燥的流水线操作,并高度重视标注人员的培训,以满足日益提高的标准数据要求。
例如,云测量数据将专门招聘一些法律和金融等垂直领域的相关人员,并对标签人员进行专业知识培训,以便他们能够猜测规格
此外,在管理过程中,云测量数据也实现了任务的合理分配,不同类型的数据人员不混合,多层交叉质量检查等。
正是这种“软实力”不仅铸就了云数据测量的能力优势,也提升了整个行业的人员素质和业务水平,并将其化为滋润整个人工智能行业的雨水。

3.捍卫底线的信念。
如果你听说过三聚氰胺、废油等食品安全事件,一旦人工智能领域出现数据安全问题,可能会损害成千上万人的财产和人身安全。
例如,许多数据是企业的最高机密。如果他们不小心从第三方平台流出,不仅会毁了企业的声誉,还会成为竞争对手的利剑,造成搬起石头砸自己脚的局面。
目前,人工智能数据行业还没有形成统一的安全规范和标准,因此企业的自我意识和技术措施尤为重要。
就云测量数据而言,已经建立了一系列安全机制。例如,客户的定制数据在交付后将不会被留下,也不会被重复使用,彻底删除将消除隐患;
此外,在收集数据时,还会与被收集方签订数据授权协议,使人工智能企业获得的数据合规合法,不存在隐私被侵犯的风险。
防火墙设置、内部信息系统、终端未连接、USB接口密封等机制也从源头上保护了客户的数据安全。
云测量数据总经理贾雨航多次公开表示,人工智能公司和数据服务公司都应该从长计议,采用未经授权的数据当然可以控制成本,野蛮开发最终会造成不良后果。
云数据测量的业务场景涵盖许多领域,如智能驾驶、智能城市、智能家居、智能金融、新零售等。所有这些都对数据安全性有极高的要求。作为人工智能数据服务的龙头企业,云测量数据的安全探索可以作为整个行业在安全合规层面的参考答案。
捍卫数据安全的底线也是这个新兴行业的生命线。

从云数据的培育中,不难发现人工智能数据解锁的每一步都充满了困难,但这也是形成产业壁垒的关键过程。
像云数据一样,在人工智能培训中不断注入安全和高质量的数据“养料”,将转化为工业优势的积累,并激发智能时代的无限可能性。
数据沃土的培育可以让我们看到人工智能吹起时麦浪的丰收。







