处处不智:人工智能数据“消费升级”才刚刚开始
“新基础设施”的哨声响起,我们一定已经从各种渠道感受到了行业情报的热度。
这一次,人工智能不再局限于“人工智能再次粉碎人类”的科幻情节,而是成为一种社会通用技术。家居、汽车、商业超级、3C产品等各个领域都开始用人工智能影子进行高频宣传。
其中,人工智能三要素的——数据、算法和计算力,是——数据中最基础、最核心的部分,自然成为了智能烹饪行业的一道美味佳肴,越来越受到人们的关注。
如果我们把工业智能的红利视为一块等待切掉的蛋糕。那么坐在电脑前一点一点地标注图片或文字的数据注释者可能就是在智慧的沃土上种小麦的人。
这些加工过的食物在被算法工程师拿走后被喂给机器,并教会它们猫、狗、行人和交通灯之间的区别。“最近天气不好”是什么意思.
听起来人工智能数据的“种植”相当简单。事实上,在人工智能的早期发展阶段,人工智能的数据收集和标记常常被视为“无障碍”的东西,甚至是新时代的血汗工厂。
然而,就像吃太多的粗粮总是会导致对健康、有机和精细加工的追求一样,人工智能数据产业已经开始了一场我们可以看到的“制造业升级”。
你和数据都想知道智能产业的味道。
尽管人工智能数据不是算法训练的唯一元素,但它绝对是不可缺少的一部分。
一方面,人工智能数据更丰富、更便宜的地区更有可能产生人工智能火焰。例如,机器翻译已经发展了几十年,积累了大量的双语对比语言材料。因此,当谈到机器学习时,它变成了一条龙。深度神经网络的引入使翻译系统的效果迅速超过基于统计模型的统计机器翻译。今天,NWT神经机器翻译已经成为智能语音产品的标准。
此外,人工智能数据的质量也决定了人工智能产品是否符合使用场景,影响用户体验甚至产品生命周期。在开采人工智能产业化富矿的过程中,人工智能数据的重要性怎么强调都不为过。
因此,一个专业的第三方人工智能数据产业链也应运而生,以满足对高质量和大规模数据的需求。
然而,当人工智能蓬勃发展时,人工智能数据产业的制约也随之而来。

首先,传统的爬虫或众包模式,数据收集多且肤浅,难以满足高性能和高精度算法对数据的需求。例如,在金融和其他场景中,银行可能要求人脸识别算法的准确率达到99.99%,以达到保护客户财产安全和防范安全风险的水平。传统的平面数据显然是不够的。需要具有更丰富维度和更多样角度的3D人脸图像来训练所需的算法。
此外,机器学习的数据依赖性也增加了人工智能训练的直接成本。无论是收集或购买数据本身的费用,还是调用数据增强等技术来增加数据样本的费用,背后都有不小的成本。
对于刚刚在人工智能学术界出现的胶囊网络、小样本甚至零样本学习,虽然不再受数据量的限制,但目前仍处于实验阶段。该行业的成熟性和稳定性是不可预测的,要实现这一目标还有很长的路要走。因此,目前以深层神经网络为核心的机器学习仍然是人工智能产业化的技术支撑。这也决定了对人工智能数据的渴求,这将伴随人工智能产业的发展一段时间。
从工业化和工程的逻辑角度来看,如果今天的企业想要创造出具有积极效果和口碑的人工智能产品,他们可能购买的通用“面粉”不再能满足挑剔的用户,他们必须学会为自己的数据培育肥沃的土壤。
晚上,当南风吹来,小麦被长长的黄色覆盖时,人工智能数据变得越来越成熟
作为新基础设施浪潮的结果,人工智能数据产业的增长速度也快于预期。
没有其他原因,数字技术和数以千计的行业的整合是当今中国的主要基调,而数据是撒在土地上的种子,等待着完成智能收获。
那么,需要什么样的种植逻辑才能使他们健康成长,有资格进入生产车间,最终成为滋养社会智力的高营养食品呢?答案也可能隐藏在中国人的“培养人才”中:
首先,尊重法律的专业化。
我们知道一些强大的科技工厂,如英美烟草公司,经常建立他们自己的数据中心来完善他们的算法。对于规模较大的企业来说,面对洪超的一条数据,爆炸性的创新将不可避免地带来数据规模的爆炸性增长。一些预测显示,到2025年,80%的计算将来自人工智能计算,涉及的数据将是180亿,比目前的数字增加了4倍。在如此庞大而复杂的数据社区中,找到最适合自己土壤的“种子”显然不是一件容易的事。

早些时候,当谷歌工程师被问及众包平台M-Turk(公共平台发布任务,参与者可以自由申请)的效果时,他们声称“收集的数据是混合的”
用人工智能的一句话来说,“垃圾进,垃圾出”,如果你喂算法垃圾食品,你很可能在没有监督学习的情况下发展成声誉崩溃的焦点。
例如,以前市场上有一个聪明的青少年演讲者,在对话中突然出现了脏话。原来,在培训过程中,数据集没有得到很好的清理,导致了不良数据的混合,使人工智能化身为“安祖”,所以制造商不得不暂时停止呼叫,再次进行大规模的内部审核。
如果受限数据被意外地再次使用,如欧盟GDPR通用数据保护条例的红线,它不仅会失去当年的收成,还可能会损失一大笔赔偿。是谷歌听到了沉默,是脸书哭了。
很难控制数据的质量,这很可能使企业的心血变成秋风中的寂寞。因此,一个更专业的数据收集和标记平台已经成为那些在正确的时间珍惜正确的地方的人工智能企业家们的必要合作伙伴。
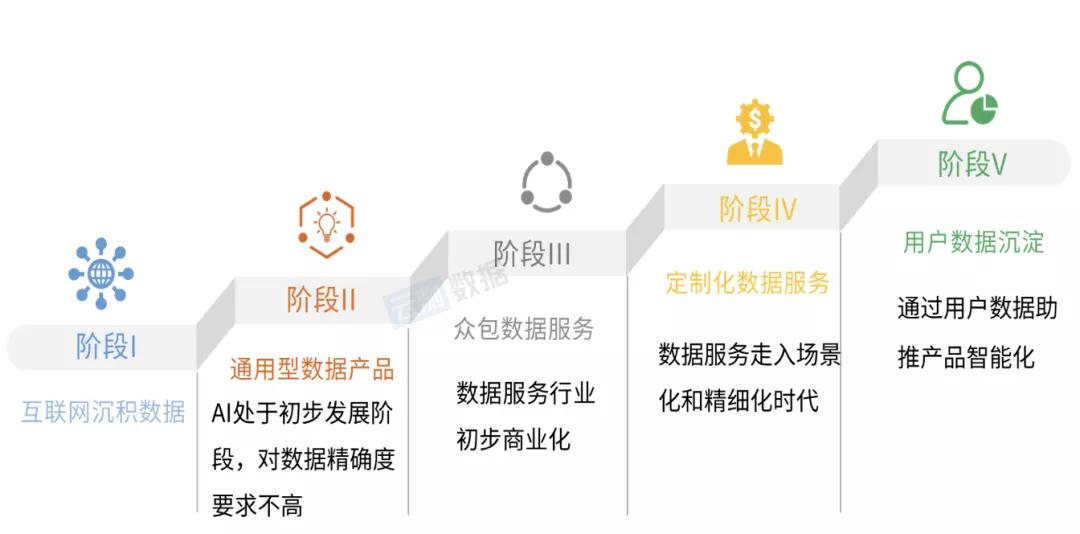
第二,现场的当地条件。
在商业人工智能数据平台中,“基于人工智能的着陆场景”是一种相对较新的模式。
开源数据集不甜蜜,还是通用数据不便宜?场景数据的流行可能与人工智能计算行业在其下一个发展中可能遇到的矛盾有关,即竞争。
我们知道人工智能现在已经成为GPT的一种通用技术,这也意味着它将以更广泛的姿态融入人类社会,在此基础上生产新产品和新技术,甚至更新生产和组织方法。
由于是GPT,这意味着泛人工智能算法不再稀缺,而是分散在日常生活中的水和空气。如何在人工智能产品中与同行竞争,从人工智能数据中重新确立自己的核心优势,已经成为科技企业的必然选择。
例如,过去,尚超没有一家商店是智能的,但现在几乎每家商店都在尝试引入智能零售解决方案。在这种情况下,拥有自己独特场景数据的超级零售商的业务所有者将能够更准确地了解自己的业务情况。例如,在此基础上,了解顾客面对货架和在地板上走动时的表情有助于判断展示计划和个性化营销推动,进一步促进转型和再购买。

这个更高级的场景数据不是一件简单的事情,要获取并交付给算法端使用。
云测量数据总经理贾亚航举了一个例子。例如,在网上订票这样的对话场景中,有很多表达方式,比如“有去XX的航班吗”和“帮我查一下机票”.如何让人工智能助手们在不同的表达方式中理解彼此的意图,需要人工智能数据服务企业与预订平台精心对接,在标注时进行适当的拆解和操作,因地制宜,将大量高质量的数据转化为垂直行业的智能养分。
一个有趣的数据是,尽管我们今天听到了太多关于人工智能的消息,但人工智能与工业结合的总渗透率只有4%。在未来很长一段时间内,值得密切关注数据场景。
第三,提高能源效率的工程。
当然,随着数字经济进入成熟期,向人工智能扔钱不说的情况已经不存在了。在选择数据模型时,企业必须考虑投入产出比。
因此,当基于场景的数据的繁重工作负载很大时,行业智能能否最大化?
答案是,不一定。基于场景的数据成本并不低,这里充分展示了“工作的人多,智慧的人多”。有一次,人工智能算法平台的一名工作人员告诉我,为了训练一个能够准确识别人体运动的模型,他们合作的3D建模数据端会雇佣人员在姿势采集中心采集好的简历数据,因为数据量太大,只能放在硬盘上,工作人员必须往返两地才能将数据发送到实验室。
这听起来一点也不“高科技”吗?
因此,如果一个工人想做好工作,他必须首先使用他的工具。随着情景人工智能数据产业的发展、工程能力的提高和效率工具的引入,情景数据的总成本将接近商业均衡点,人工智能企业的成本风险将降低。
很明显,人工智能数据的可视化不仅是工业人工智能的唯一途径,而且还被大量等待钻穿的冰密集覆盖。
穿透数据冰:云数据如何在行业中发展人工智能
当社会经济和智能技术开始结合时,场景数据的工业服务提供商也开始出现。
目前,成立于2011年的Testin cloud measurement已成为中国市场上人工智能数据可视化的首选,其人工智能数据采集和标注品牌为—— cloud measurement data。
人工智能数据土壤上的冰层是如何被云数据抹去的?
1.手锄犁五金。
场景数据的采集和标注有很多难点。例如,自然语言处理、计算机视觉等,不仅需要标注者准确理解相关语义,还需要根据具体的工业需求进行标注。
为了保证人工智能数据的高质量交付,云测量数据在华东、华北和华南地区设有数据标注基地和数据采集现场实验室,确保人工智能数据的专业化、场景化和精细化。
贾亚航(云测量数据总经理)给了我们一个例子。为了帮助疲劳检测系统准确判断驾驶员的状态,疲劳状态数据是必不可少的。因此,云测量数据将恢复驾驶场景中的疲劳驾驶状态,有助于收集符合真实场景的疲劳数据。该训练算法模型能够准确识别并及时报警,保护人员的交通安全。
此外,为了提高人工智能数据的标注效率,云数据还开发了许多工程工具来不断提高数据标注工具的技术含量。
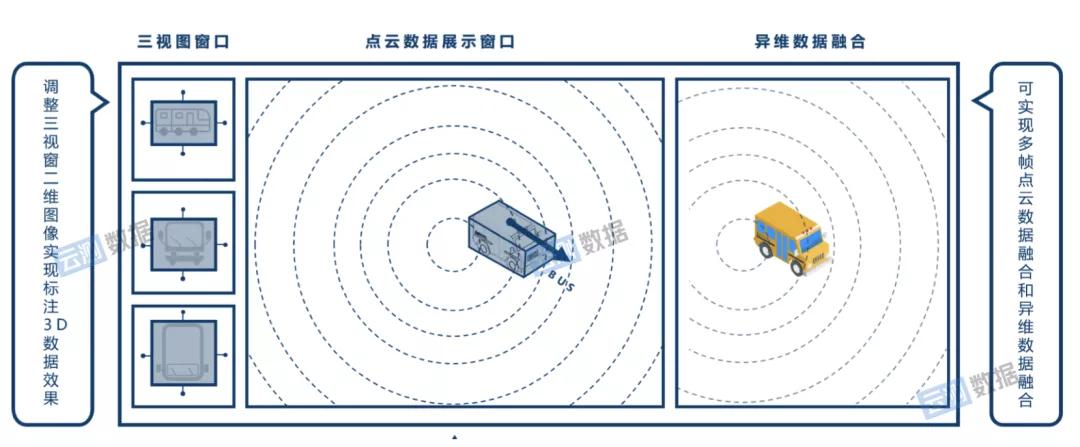
例如,在云测量数据自主研发的数据标注平台上,渲染引擎针对3D点云标注系统进行了优化,可以融合多帧点云数据和不同维度的数据,使数据视图一目了然,保证整个过程的流畅和快捷,从而减轻标注人员的重复劳动压力。
2.悄悄滋润事物的软件。
在人工智能世界里,我们总是强调硬件——更强的计算能力、更好的数据和更好的算法。拥有这些意味着一切吗?显然情况并非如此,否则迪普迈德将是最成功的商业人工智能公司。
从技术概念到行业落地的管理逻辑就像行业上空的春雨,“风悄悄潜入夜,润物细无声”。
我们都知道“好雨知道季节”和“好”在哪里?
幸运的是,在正确的时间。例如,Testin cloud measurement在企业服务领域积累了近9年的经验。其管理模式也使得数据采集和标注不再是枯燥的流水线工作,并高度重视标注人员的培训,以满足日益提高的标准数据要求。
例如,云数据将专门招聘一些法律、金融等垂直领域的相关人员,并对标签人员进行专业知识培训,以便
此外,在管理过程中,云测量数据也实现了任务的合理分配,不同类型数据的人员不混杂,多层次交叉质量检查等。
正是这种“软实力”不仅铸就了云测量数据的能力优势,还提升了整个行业的人员素质和业务水平,并将其转化为滋养整个人工智能行业的雨水。

3.捍卫底线的信念。
如果你听说过诸如三聚氰胺和非法食用油等食品安全事件,如果人工智能中存在数据安全问题,可能会对成千上万人的财产和人身安全造成损害。
例如,大量数据是企业的最高机密。如果是从第三方平台意外泄露的,不仅会败坏企业的声誉,还会成为竞争对手的利剑,造成斯通自食其力的局面。
目前,人工智能数据行业尚未形成统一的安全标准,因此企业的自我意识和技术措施尤为重要。
就云数据而言,已经建立了一系列安全机制。例如,为客户定制的数据在交付后将不会被留下或重复使用,从而消除了泄露的隐患。
此外,在数据收集过程中,还将与被收集方签订数据授权协议,使人工智能企业获得的所有数据都符合法律法规,且无需担心隐私被侵犯的风险。
防火墙设置、内部信息系统、终端断开连接、USB接口阻塞等机制也从源头上保护了客户的数据安全。
贾晓阳(云测量数据总经理)也曾多次公开表示,人工智能和数据服务公司都应该从长计议,使用未经授权的数据来控制成本。野蛮的发展最终会导致不良后果。
云测量数据的业务场景涵盖了智能驾驶、智能城市、智能家居、智能金融、新零售等多个领域,所有这些都要求极高的数据安全要求。作为人工智能数据服务的龙头企业,云测量数据的安全探索可以作为整个行业在安全和合规层面的参考答案。
捍卫数据安全的底线也是这个新兴行业的生命线。

从云测量数据的培育中,不难发现,人工智能数据解锁的每一步虽然充满了困难,但也是形成产业壁垒的关键过程。
为人工智能培训持续注入安全和高质量的数据“养分”,如云数据,将转化为工业优势的积累,并利用智能时代的无限可能性。
为数据培育肥沃的土壤将使我们能够在人工智能吹起时看到丰收的麦浪。







