充满“人工智能核武器”的英伟达如何赢得人工智能来计算新的竞技场?
在2012年图像网络挑战赛上,深度卷积神经网络AlexNet诞生,在图像分类和识别领域实现了质的飞跃。它被认为是人工智能时代的里程碑事件,代表了深度学习时代的正式开始。
在此之前,深入学习“如何围成一个圈”的主要挑战之一是,深入的神经网络训练面临计算能力不足的问题。AlexNet在计算能力方面取得突破的关键在于,当时研究人员使用了Avida的图形处理器。
GPU在第一次世界大战中成名,并成为随着人工智能技术发展的基础设施。英伟达也抓住了人工智能计算的新增长机遇。随着人工智能计算能力需求的爆炸性增长,Avida图形处理器产品经历了几轮升级。
现在,Avida的图形处理器家族正在经历历史上另一次“最大”的性能升级。这次升级是在“表面上最强的人工智能芯片”特斯拉V100最后一次发布三年后进行的。
经过三年的休眠,它成了一部轰动一时的电影。

(英伟达A100图形处理器)
英伟达是第一个引入第八代安培图形处理器架构的公司,也是第一个基于安培架构的英伟达A100图形处理器。使用7纳米工艺,英伟达在一个晶片上放置了超过540亿个晶体管,面积几乎与上一代伏打架构的V100图形处理器相同。晶体管的数量增加了2.5倍,但尺寸只增加了1.3%。在人工智能训练和推理计算能力方面,两者都比上一代伏打架构高出20倍,高性能计算性能提高了2.5倍。
A100图形处理器的独特之处在于,作为一个端到端的机器学习加速器,它首次将人工智能培训和推理统一在一个平台上,并且还将作为数据分析、科学计算和云图形设计等常见工作负载的加速器。简而言之,A100图形处理器是为数据中心创建的。
在A100图形处理器的基础上,Avida同时发布了世界上最强的人工智能和高性能计算服务器平台——HGX A100,世界上最先进的人工智能系统——DGX A100,以及由140个DGX A100系统组成的DGX超级集群。此外,还有与智能网卡、边缘人工智能服务器、自动驾驶平台合作以及一系列软件级版本相关的基于平台的产品。
可以说,英伟达这次不是在释放“核弹”,而是一个“核炸弹集群”或一种饱和攻击。从云到边缘到终端,从硬件到软件到开源生态,Avida几乎为人工智能计算建立了一个坚不可摧的屏障,同时也将人工智能芯片的竞争提升到了小玩家无法企及的水平。
Avida的人工智能服务器芯片业务正在发生什么新的变化?A100图形处理器的发布对人工智能服务器芯片市场有什么影响?它将给云计算市场带来什么变化?这已经成为我们在观看激动人心的比赛时应该关注的几个问题。
人工智能服务器芯片:Avida人工智能计算发展的新亮点
众所周知,游戏、数据中心、专业可视化和自动驾驶等新业务是Avida的四大核心业务领域。其中,虽然游戏业务仍然是收入的支柱,但由于个人电脑游戏市场的饱和和向移动端的转移,独家显示业务的比例正在逐渐萎缩。专业可视化业务为Avida贡献了稳定的收入,但由于其他业务增长的影响,其业务比例也持续下降。自动驾驶等新业务部门目前仅占应收账款总额的一小部分,增长率有限,但可以被视为Avida未来的长期市场。
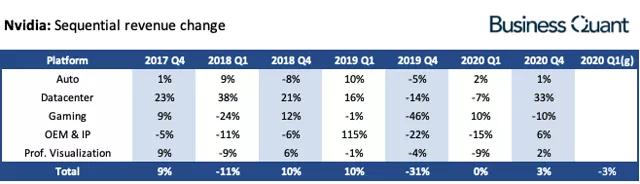
(英伟达:连续收入变化)
最明显的是英特尔在数据中心业务领域的增长。近年来,其收入大部分时间都在高速增长,收入份额逐渐接近游戏业务。
根据Avida最新的2020财年第四季度财务报告,“游戏”收入达到14.9亿美元,约占总收入的47%。在增长强劲的数据中心领域,智能服务器芯片的收入达到9.68亿美元,同比增长42.6%,接近10亿美元,远远超过8.29亿美元的市场预期。
总的来说,随着全球数据中心对人工智能芯片需求的加速增长,尤其是在超大型数据中心,Avida的人工智能服务器芯片正在经历快速增长,并正在成为Avida最具市场扩展潜力的业务分支。
从业务增长的角度来看,Avida正在推出A100 GPU服务器芯片和人工智能系统集群,以保持人工智能服务器市场在当前数据中心的主导地位。
那么,Avida是如何为这个人工智能服务器芯片构建产品系统的呢?
一般来说,对于深层神经网络算法模型,模型框架的训练需要涉及非常大的数据计算,但计算方法相对简单,因此需要在云中进行大量的高并行、高效率和高数据传输的操作。因此,与擅长复杂逻辑运算但内核较少的中央处理器相比,多计算单元的GPU更适合深度神经网络训练任务。
这是Avida的图形处理器在全球云人工智能服务器芯片市场赢得市场领先地位的根本原因,尤其是在培训方面。与此同时,Avida为一系列人工智能服务提供的完整的特斯拉图形处理器产品系列,以及其为图形处理器成功设计的“CUDA”开发平台,是Avida在人工智能服务器芯片市场占据主导地位的主要原因。
从2016年推出第一款针对深度学习而优化的帕斯卡图形处理器,到2017年推出性能比帕斯卡高五倍的新图形处理器架构——伏打,再到性能比伏打高20倍的安培架构——Avida在数据中心的图形处理器产品已经成功实现了高速、稳定的性能提升。
此外,Nvidia还推出了神经网络推理加速器TensorRT,它可以为深度学习应用程序提供低延迟和高吞吐量的部署推理加速,并与几乎所有当前主流的深度学习框架兼容,使其能够满足从人工智能培训到超大型数据中心部署推理的完整人工智能构建。
去年3月,Avida宣布以68亿美元收购以色列网络通信芯片公司Mellanox。通过集成Mellanox的加速网络平台,Avida可以解决通过智能网络结构连接大量快速计算节点的问题,形成一个庞大的数据中心规模计算引擎的整体架构。
在A100图形处理器发布的同时,Avida还推出了世界上首个基于Mellanox技术的高度安全高效的25G/50G以太网智能网卡,将广泛应用于大型云计算数据中心,极大地优化了网络和存储的工作量,实现了人工智能计算更高的安全性和网络连接效率。
当然,购买Mellanox的意义不止于此。除了解决高性能网络连接和计算能力输出的问题,英伟达还将拥有三个处理器,分别是GPU、SoC和NPU,它们面向不同的子域。这意味着英伟达基本上有能力独立构建人工智能数据中心。
总的来说,随着云数据中心从传统数据存储向深度学习、高性能计算(HPC)和大数据分析发展,Avida也将作为人工智能计算服务提供商发挥更重要的作用。
在英伟达的高墙之外,人工智能计算竞争加剧
当然,云人工智能服务器芯片市场远非一成不变,但将在2019年面临最激烈的竞争。
由于高能耗和高价格,Avida的图形处理器产品一直在限制云计算数据中心人工智能计算能力的成本。从服务器芯片市场的另一大玩家英特尔,到AMD和高通,云计算服务提供商亚马逊、谷歌、阿里、华为和许多新兴的人工智能芯片初创公司都在积极投资于云人工智能服务器芯片的研发,并寻求替代GPU的解决方案。可以看出,世界正长期遭受“GPU”的困扰。
2019年,与Avida的轻微沉默相比,其他公司推出了自己的人工智能服务器芯片产品。例如,去年上半年,英特尔、亚马逊、脸谱和高通相继推出或宣布了他们自己的专用人工智能服务器芯片,试图在人工智能推理计算中取代GPU和FPGA。年中,中国主要云人工智能制造商也做出了集体努力。寒武纪在六月宣布推出第二代云人工智能芯片允祀270。8月,华为正式发布了最强大的人工智能处理器——腾胜910和MindSpore全场景人工智能计算框架。9月,阿里推出了当时被称为世界上最强的800光人工智能推理芯片,基本上都是针对Avida的T4系列产品。

在所有人工智能芯片的竞争对手中,排在第二位的英特尔显然想挑战Avida的霸主地位,也是最有可能挑战Avida的代表。
作为通用服务器芯片的传统巨头,英特尔最有可能的策略是将GPU和人工智能集成到其CISC指令集和CPU生态中,即同时部署CPU和GPU。云服务提供商只需购买一种产品,就能更好地展示人工智能计算的效率。
他们是如何在全智能英特尔构建这一智能计算战略的?
英特尔的第一个补充是人工智能硬件平台布局,收购是最快的解决方案。2015年,英特尔首次以天价收购了FPGA制造商Altera。一年后,英特尔收购了Nervana,为新一代人工智能加速器芯片组奠定了基础。
去年12月,英特尔又斥资20亿美元收购了位于以色列数据中心的人工智能芯片制造商哈伯纳实验室(Habana Labs),该公司成立仅三年。对哈瓦那的收购将补充英特尔在数据中心领域的通信和人工智能能力。
受到此次收购的鼓舞,英特尔宣布将停止仅在去年8月发布的用于人工智能培训的Nervana Nnp-T,转而专注于向Avida的特斯拉V100和推理芯片T4推广Habana实验室的高迪和Goya处理器产品。此外,基于Xe架构的图形处理器也将在今年年中推出。
在软件层面,为了应对异构计算带来的挑战,Avida于去年11月发布了OneAPI公开版。无论是中央处理器、图形处理器、现场可编程门阵列还是加速器,OneAPI都试图在最大程度上简化和统一SVMS架构中的这些创新,以释放硬件性能。
尽管英特尔在人工智能计算领域采取“全力以赴”的态度,但它已经收集了覆盖图形处理器、现场可编程门阵列和专用集成电路的人工智能芯片产品阵列,并建立了广泛适用的软硬件生态。然而,挑战Avida的通用图形处理器产品还有很长的路要走。

首先,英特尔将中央处理器应用于人工智能计算的策略并没有受到主要云计算供应商的青睐。大多数供应商仍然愿意选择中央处理器图形处理器或现场可编程门阵列来部署他们的人工智能培训硬件解决方案。虽然图形处理器仍然是Avida的家,但V100和T4仍然是数据中心的主流通用图形处理器和推理加速器。
其次,英特尔人工智能芯片的布局才刚刚开始。由于Nervana人工智能芯片的一再延迟,Habana产品才刚刚开始集成,这将使英特尔难以在短期内挑战Avida的人工智能服务器芯片市场份额。
然而,英伟达最新安培架构A100图形处理器和人工智能系统集群的发布是对英特尔和市场上其他竞争对手的饱和攻击。虽然据说云计算制造商和人工智能服务器芯片制造商开发的定制芯片从长远来看将会侵蚀一部分GPU的份额,但他们现在必须超越由Avida A100构建的人工智能计算的坚硬高墙。
人工智能计算升级为数据中心带来新的布局规划
让我们先看看数据中心本身的变化。由于与人工智能相关的应用需求和场景的爆炸式增长,中小型数据中心无法承受如此巨大的“人工智能计算之痛”,超大型数据中心的市场需求日益强劲。
首先,以亚马逊AWS、微软Azure、阿里和谷歌为代表的公共云巨头占据了超大型数据中心的主要市场份额。一方面,超大型数据中心将带来更多服务器和支持硬件增长;另一方面,人工智能算法日益复杂,人工智能处理任务不断增加,要求服务器配置和结构不断升级。
在一些专注于视觉识别的人工智能企业中,超级计算中心的建立需要部署数万个GPU单元。对于顶级云服务提供商的云计算数据中心来说,支持深度学习和培训任务所需的图形处理器级别也将是巨大的。
其次,云服务制造商正在引入自主开发的芯片,以缓解因价格高和数据量大而导致的GPU计算成本飙升的问题。这些制造商推出的大多数推理芯片都是为了节省GPU的一般计算能力。然而,这些推理芯片的通用性不足,难以突破自我研究和自我使用的局面。
那么,Avida的A100图形处理器芯片将给云计算数据中心带来什么新的变化呢?或者对人工智能服务器芯片的反对者设定了什么门槛?
首先,作为一款全新安培架构的A100图形处理器,它支持每秒1.5TB的缓冲带宽处理,支持TF32运算和FP64双精度运算,分别是FP32的20倍和高性能计算应用的2.5倍。此外,它还包括米格公司的新架构,NVLink 3.0和人工智能计算结构的稀疏性,使A100加速器卡不仅适用于人工智能训练和人工智能推理,还适用于各种通用计算能力,如科学模拟,人工智能对话,基因组和高性能数据分析,地震建模和金融计算。然而,这种解决方案可能会减轻许多云服务供应商在推理方面的计算压力,并给其他供应商的推理芯片带来一定的竞争压力。
其次,Avida发布的第三代DGX A100人工智能系统大大降低了数据中心的成本,同时提高了吞吐量。因为A100内置了新的灵活计算技术,所以它可以以分布式方式灵活拆分。多实例图形处理器能力允许每个A100图形处理器分成七个独立的实例来推断任务,多个A100也可以作为一个巨大的图形处理器来运行,以完成更大的训练任务。

(“你买的越多,存的钱就越多!”)
以黄仁勋为例,一个典型的人工智能数据中心有50个用于人工智能训练的DGX-1系统和600个用于人工智能推理的中央处理器系统。它需要25个机架,消耗630千瓦的电力,成本超过1100万美元。为了完成相同的工作,由5个DGX A100系统组成的机架可以满足相同的性能要求。只有一个机架消耗28千瓦的电力,成本约为100万美元。
换句话说,DGX A100系统可以用1/10的成本、1/20的功耗和1/25的空间替换整个人工智能数据中心。

总的来说,Avida为人工智能数据中心计算平台带来了新的升级,拥有一套令人惊叹的创新人工智能计算架构和人工智能服务器芯片硬件。英伟达的雄心将不再仅仅是提供性能升级的GPU硬件产品,而是重新定义数据中心的人工智能计算规则,并将数据中心视为一个基本计算单元。
事实上,DGX A100图形处理器系统的单价是20万美元。对于那些想购买数千个企业级图形处理器进行人工智能培训的云计算供应商来说,可以想象成本会有多高。目前,只有世界主要云计算制造商、信息技术巨头、政府和实验室为DGX A100下了初始订单。
对其他竞争对手来说,Avida在人工智能服务器芯片和人工智能数据中心计算平台上打造的坚实墙在短期内似乎无法逾越。同时,它也将成为未来几年内人工智能服务器芯片制造商的性能标准。当然,对英伟达A100的挑战自然会开始。至于是英特尔、AMD、AWS还是谷歌,我们将拭目以待。$ NVDA)$







