当人工智能开始寻找抗生素:人类终于收获“高挂果实”?
不管人们说了多少奉承的话,抗生素带来的好处怎么强调都不为过。在应用之初,抗生素被认为是治疗几乎所有疾病的灵丹妙药,并成为20世纪人类最伟大的成就之一。

(图片:感谢青霉素,给我回家的路)
然而,今天,世界上每年大约有50%的抗生素被滥用,在中国甚至接近80%。恐怕家里有孩子的人有更多的个人经历。只要孩子有头痛和发烧,他们总是需要去医院打点滴。他们中的大多数人都服用了抗生素。人们痴迷于“速效”的直接后果是使细菌对药物更具耐药性。由于细菌耐药性的增加,以前有效的抗生素可能会变得无效。
对抗生素寄予厚望的普通人可能会想:科学家只需要找到比产生耐药细菌的抗生素更强的抗生素。事实上,科学家是这样做的,但是抗生素的研究远没有人们想象的那么简单。
对于那些更不耐烦、更沉迷于“银弹思维”的吃瓜者来说,他们总是想打破常规,问自己:有没有可能找到一种能有效消除大量有害细菌的抗生素?从生物定律来看,这有点痴心妄想。但是总有目标。如果他们很接近呢?
要瓜,就得瓜。2月20日,世界著名的自然科学杂志《细胞》 (Cell)发表了一篇名为“发现抗生素的深度学习方法”的研究论文,报告称麻省理工学院的研究团队使用深度学习模型发现了一种超级抗生素——Halicin。通过实验研究,该新型抗生素化合物对多种耐药菌具有杀菌作用,并具有广谱抗菌作用。当然,本研究的亮点在于新的研究方法,即通过人工智能的深度学习算法从大型合成化学分子库中发现独特的分子结构。
人工智能开发药物的能力不再罕见,但抗生素的发现还是第一次。好奇心一定会驱使我们继续问:为什么人类开发抗生素的速度不等于细菌耐药性的增长率?人工智能对于医学探索抗生素研发的道路意味着什么?
抗生素发现之谜:为什么人类的道路更窄?
从1928年开始,弗莱明发现了——青霉素,这是几十年来第一种抗生素。从那时起,科学家已经发现了100多种抗生素。然而,从1987年到2015年,28年来,没有发现新的抗生素。
为什么新抗生素的发现越来越慢,甚至差距如此之大?可以说,我们目前使用的主要抗生素是在20世纪40年代和50年代发现的,它们都是从土壤中的微生物种群中筛选和培养出来的。约99%的细菌群体以前无法在实验室单独培养,这限制了人们分离由细菌单独产生的潜在有效抗生素化合物的能力。
自20世纪60年代以来,从微生物种群中寻找新抗生素的速度明显放缓,取而代之的是“半合成抗生素”。目前以青霉素和头孢菌素为主要成分的-内酰胺类抗生素已成为最重要的化疗药物。
直到2015年,美国科学家才发现了一种新的抗生素——泰克霉素。这种抗生素在抗菌药物领域取得了重大突破,杀死了多种致命的病原体,而病原体很难对它们产生耐药性。这一科学进步得益于细菌培养技术的进步。通过一个名为iChip的电子芯片设备,研究人员可以分离目标细菌,并在比实验室更自然的土壤环境中培养它们,从而将细菌的生长几率从1%提高到50%。
然而,寻找新抗生素的效率仍然太低,并且通过大规模投资培养的抗生素可能是旧的抗生素或者不具有良好的抗菌活性。那为什么这次人工智能能做到呢?
看点看豹:人工智能探索新抗生素的新途径
由于传统抗生素药物培养的低效率,从大型合成化学文库中筛选抗生素分子结构已成为一种新的思路。然而,这些文库可能包含数十万到数百万个化学分子,但是分子式的化学多样性是有限的,并且不能反映抗生素分子的可能化学性质。一是人工筛选的工作量非常大,成本太高。另一个是很难验证化合物的多样性。
从分子库中选择能够抑制某些细菌的分子,然后验证这些分子与已经应用的抗生素之间的差异。它包括大量的计算和重复的实验,这使得这种方法对人类研究者非常不友好。
但这一次,人工智能作为一种新的研究方法被引入,用于筛选这些合成化学物质,使得抗生素的发现成为一个重要的转折点。研究者提出了结构分析和筛选相结合的思想,利用机器学习算法从分子性质预测具有潜在抗菌性能的化合物。这一次非常成功。
首先,研究人员选择2335个经美国食品和药物管理局批准的药物分子或天然化合物分子进行筛选,目的是抑制某些大肠杆菌,然后根据80%的生长抑制率将它们分为有抑菌作用和无抑菌作用两类,作为神经网络的训练数据集。
同时,他们采用了“定向信息传递深度神经网络”(DMP-DNN)算法,多次以连续向量的形式重复传递化合物的原子和成键信息,从而获得更高层次的表征结果。这种神经网络通过自学习向量来表征分子,并且不需要人工标记特定的分子结构。
有向信息传输网络可以从分子图结构中直接预测分子属性。经过固定数量的信息传递步骤,最终形成的分子的单一载体可以预测细菌的抑制率。这种观察斑点和观察豹子的方式大大缩短了筛选路径,减少了计算和时间等成本。
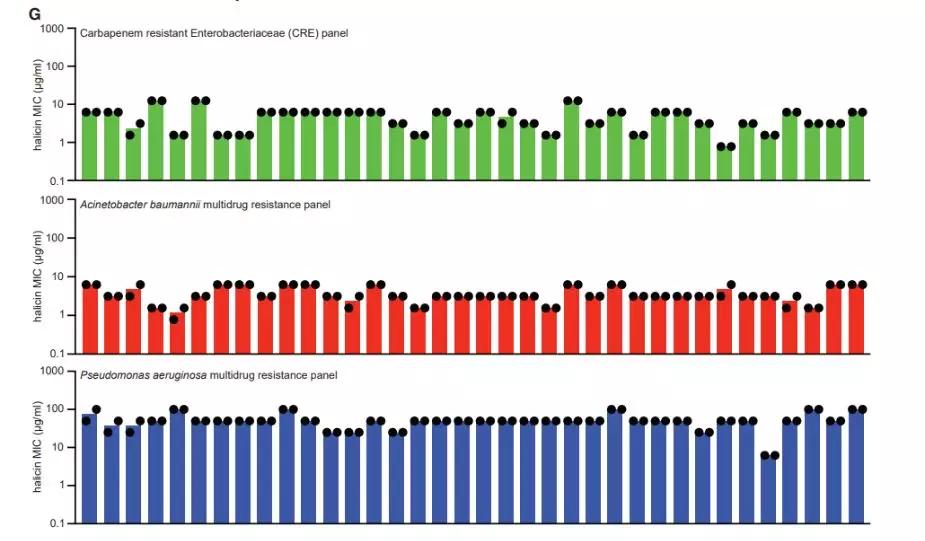
(在除绿脓杆菌(底部为蓝色)之外的几种耐药细菌试验中,哈利星显示出良好的广谱抗菌活性
随后,将训练好的深度学习模型应用到包含约1亿分子量的波德研究所DRH复合文库中进行筛选。该模型从目前正在研究的6111种药物分子中选出99种最有可能具有抑菌作用的化合物。
最后,实验结果表明,其中51株能明显抑制这类大肠杆菌的生长。名为哈利星的化合物就是从这一组中选出的,由于其低毒性和结构新颖,它已成为最有潜力的新抗生素。
此后,研究人员将再培训的深度学习模型应用于更大的锌15药物小分子数据库,预测并筛选了约1亿种化合物,并发现了新的潜在抗生素结构。筛选过程只花了三天。
可以看出,在深入学习的帮助下,6111个药物分子被筛选成99个,当这99个药物分子再次被测试时,效率自然要快得多。
这项开创性的研究标志着抗生素和更常见的新药发现方法的发现模式的转变。人工智能还能带来什么价值?
人工智能正在攻击新抗生素药物研发的战场。
一般来说,传统药物的研发主要经历这四个阶段:
1.目标的选择和确认;2.先导化合物的发现和优化;3.临床前研究;4.临床试验。只有这样,它才能被正式批准上市。一种新药从研发到上市面临三个“10”考验:10年,10亿美元,10%的成功率,而且这种趋势更加严重。抗生素的研发也面临着长期高投入、低产出、低利润的问题。
借助人工智能,特别是深度学习算法,药物研发正迎来一个新的转折点。从目前人工智能已经投入使用的新药开发和新抗生素化合物分子的发现来看,人工智能已经显示出非常明显的效果。可以说,人工智能将在未来的新药发现、化合物筛选、靶点发现和药物疗效预测中发挥巨大的辅助作用,在一定程度上提高研发效率,节约资金,降低临床试验失败的风险。

现代药物研发中最重要的事情是发现和识别药物靶标。药物靶标是指药物在体内的结合位点,包括基因位点、受体、酶、离子通道、核酸和其他生物大分子。选择和确定新的有效药物靶点是新药开发的首要任务。在人工智能技术引入之前,传统抗生素新靶标的筛选是基于基因组、抑制蛋白质合成、合成酶等方法。难点在于人工筛选测试效率低、进度慢。然而,通过人工智能深度学习模型的介入,有可能更快地在数以千万计的科学文献和这些生物体的基因分子的非结构化数据中找到可能的合适目标。通过选择不同的靶标并进行验证,可以了解靶标的生物学特性,并通过实时交互获得证据结果,从而实现相应药物靶标的发现。
此外,人工智能在筛选新药化合物时同样有效和准确。高活性化合物哈利星的发现,根据特定的药物靶向要求,使用灵活的模型算法在数千种可能的分子组成中有效地筛选出可能的药物分子结构,从而大大节省了筛选时间和成本。
此外,除了发现新的药物靶点和高活性化合物外,人工智能在小分子药物自动合成路线的设计、新药物效应的模拟和预测,甚至新药物分子的预测方面都有实际应用。这将为抗生素类药物和更一般药物的研发带来巨大的机遇。
在新药研发领域,有一种说法是那些“下垂的果实”已经被摘下来了。今后,新药研发需要在被茂密枝叶堵塞的果树高度进行。人工智能可能是到达这些树枝并收获果实的最佳步骤。







